文字识别任务#
从数据上传、模型训练、模型转换、模型部署和模型预测5个方面介绍使用Coovally训练文字识别任务的全流程。
数据上传#
数据集格式介绍 :支持OCRDataset格式。
数据准备#
将数据中的图片所在文件夹压缩为zip格式的压缩包。
将数据中的标签所在文件夹压缩为zip格式的压缩包。
创建数据集#
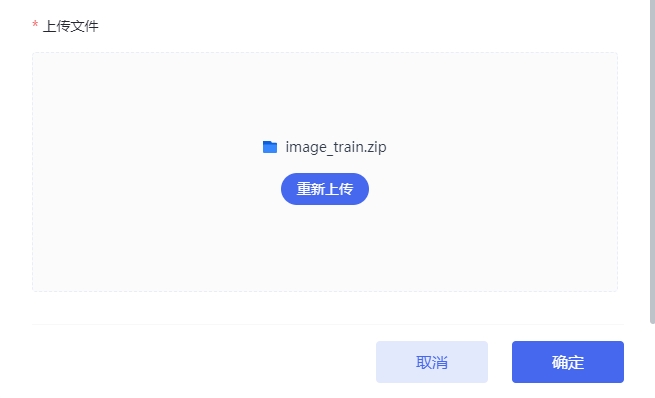
登陆Coovally平台。点击主界面左侧的图像数据,点击左上角的创建,点击创建数据集。
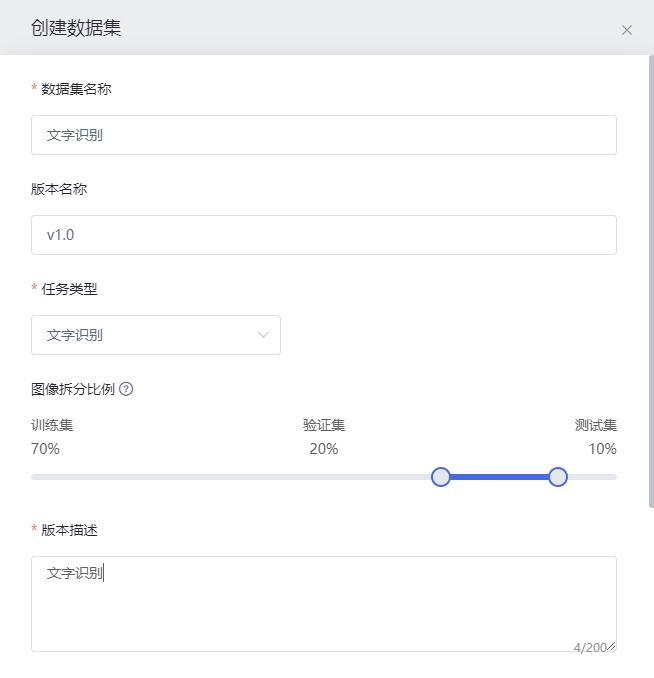
填写数据集参数,点击确定。参数说明:
1.数据集名称:自定义
2.版本名称:自定义
3.任务类型:文字识别
4.图像拆分比例:自定义设置数据集拆分比例
5.版本描述:数据集描述
6.上传文件:图片压缩包
标签上传#
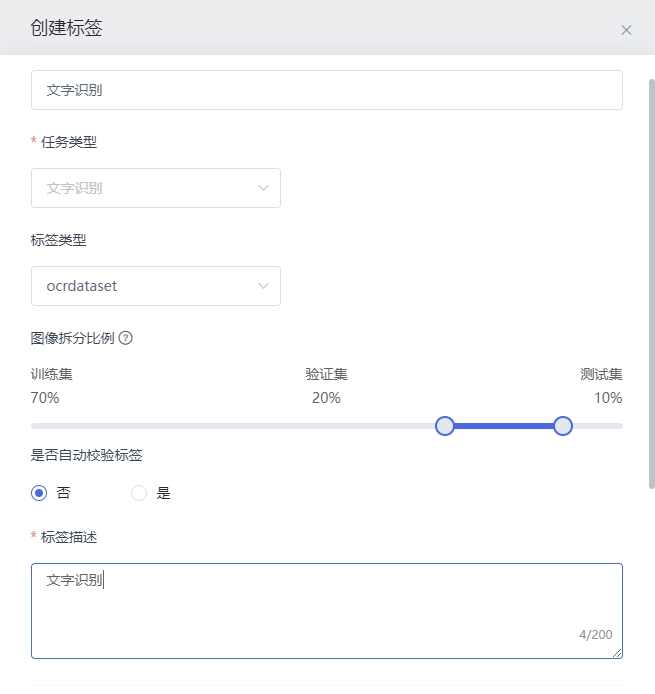
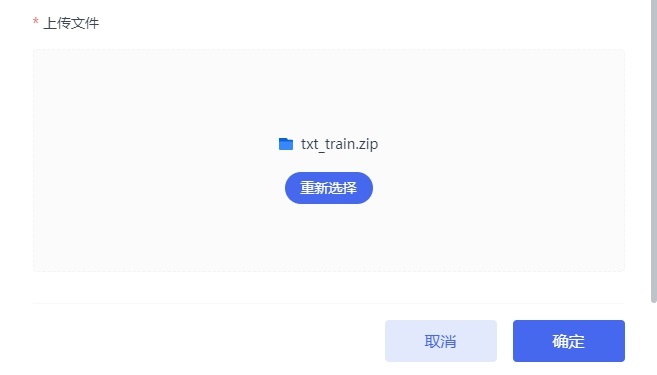
在我的数据页面,选择上一步上传的数据集,点击进入数据集详情页,点击右下角创建标签,填写参数,在文件上传区域上传标签压缩包。点击确定。参数说明:
:
1.标签名称:自定义 2.任务类型:文字识别 3.标签类型:选择上传标签的文件类型 4.图像拆分比例:自定义 5.是否自动校验标签:选择是/否。是:系统自动修复上传标签文件中越界的标签数据集;否:不自动修复 6.标签名称:输入标签名称 7.上传文件:标签压缩包
模型训练#
点击主界面图像数据,选择我的数据,选择刚刚上传的数据集,进入数据集详情页。
点击标签列表中的开始训练,选择系统算法,进入参数设置页面。
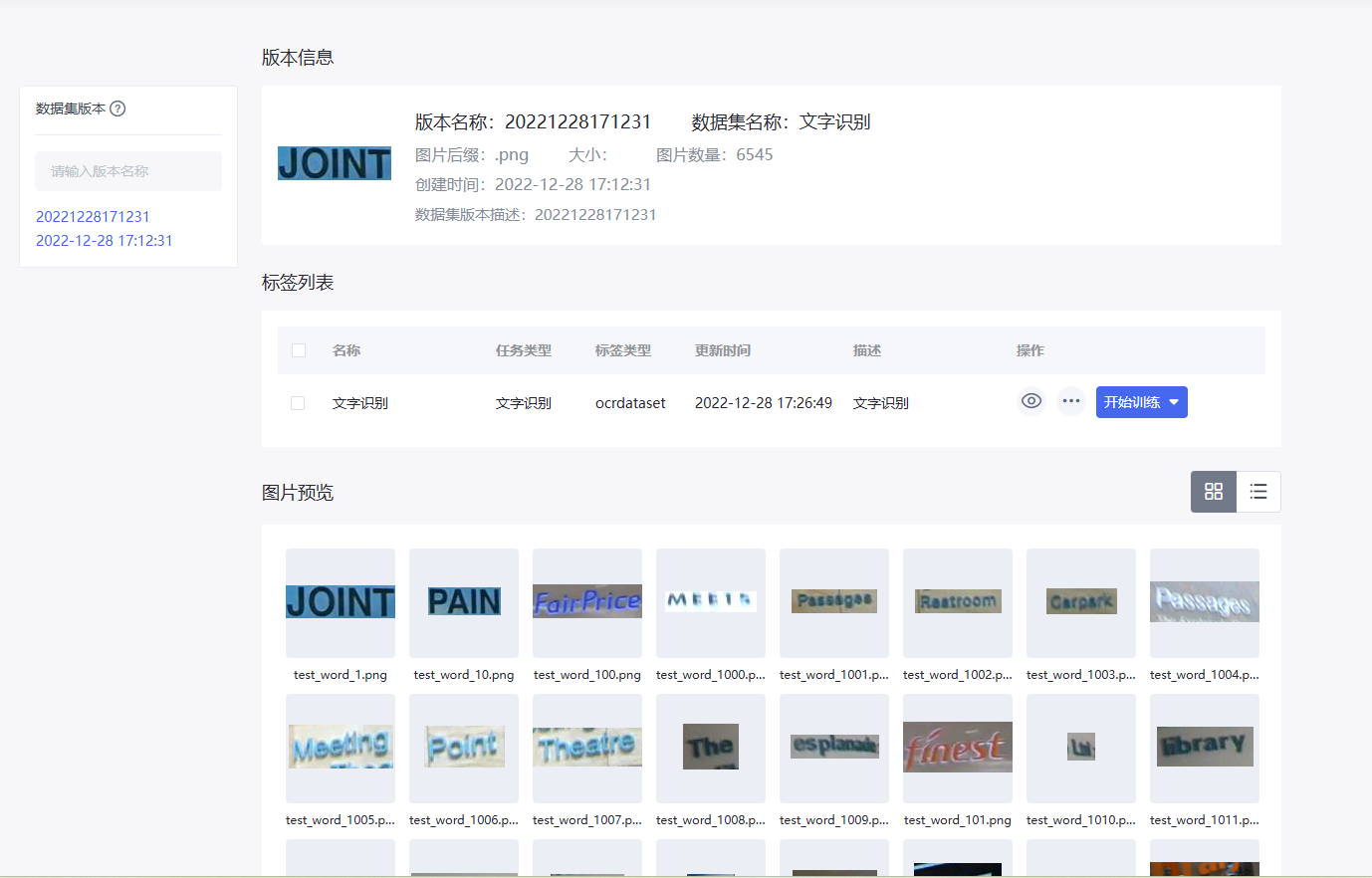
填写模型参数和实验参数。
模型参数
任务名称:自定义
任务类型:文字识别
算法名称:自定义
评估方法:保持默认方法
镜像地址:保持默认地址
是否复用:是否希望后续模型以该模型为基础模型,在此基础上进行微调
实验参数
每次实验epoch:自定义,指训练集中全部样本训练的次数
实验次数:自定义,指模型训练总次数
并发次数:自定义,指并行训练的数量
持续时间:设置本次训练可持续的最长时间
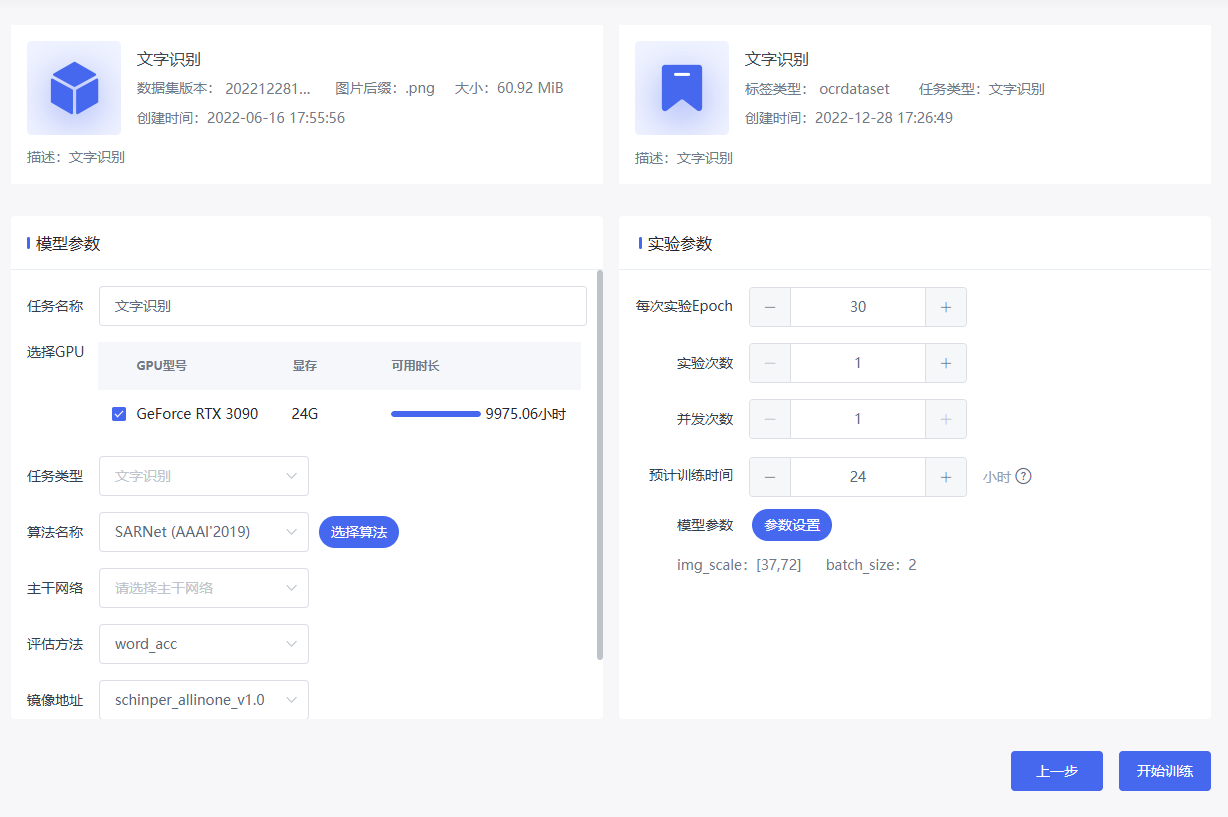
点击参数设置进入超参数设置页面,设置合适的超参数值,以提高模型精度或加快训练模型速度。参数非必填,可使用默认值。
设置内容:模型输入尺寸宽高、合适的Batch-Size选择。模型输入尺寸越大,模型精度越高,但训练、推理速度会相应变慢。
模型训练
点击开始训练,即开始训练模型。模型训练过程中可以查看各项指标。
模型训练任务创建完成后,点击总览页面,展示模型训练的相关信息,包括任务执行状态,任务持续时长、训练列表、最佳指标等关键信息。后续可进行模型转换、部署、预测等操作。
模型转换#
点击实验详情下的实验列表,进入模型转换页面,点击模型转换图标  ,选择模型格式类型、机器架构、设备、服务器、模型精度,填写模型名称和描述,点击开始转换开始进行模型转换,等待模型转换完成即可。
,选择模型格式类型、机器架构、设备、服务器、模型精度,填写模型名称和描述,点击开始转换开始进行模型转换,等待模型转换完成即可。
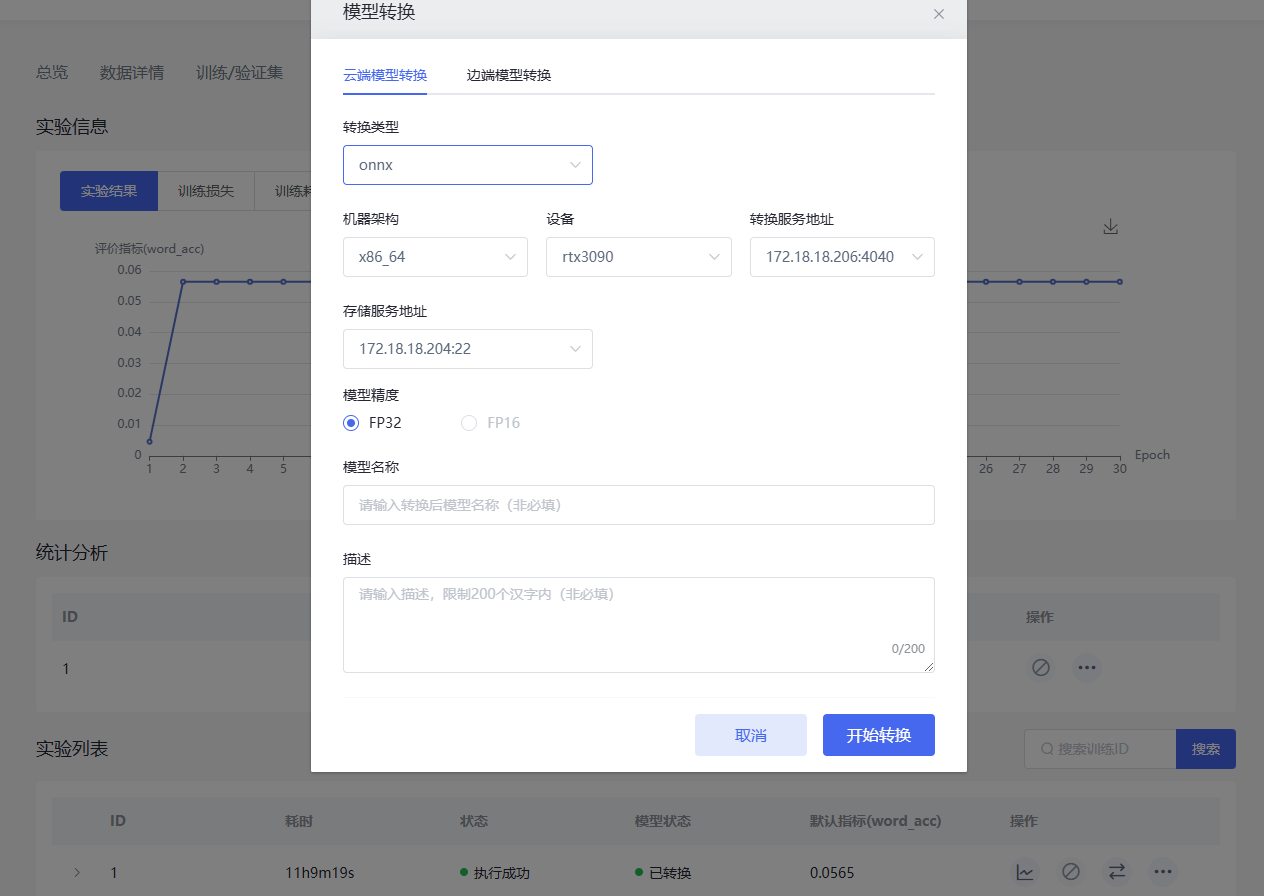
模型转换详细信息可参考模型转换。
模型部署#
在模型转换完成后,点击模型预测,点击模型列表下模型部署图标 ,打开模型部署页面,按要求选择服务地址,再点击部署按钮,等待部署完成。
,打开模型部署页面,按要求选择服务地址,再点击部署按钮,等待部署完成。
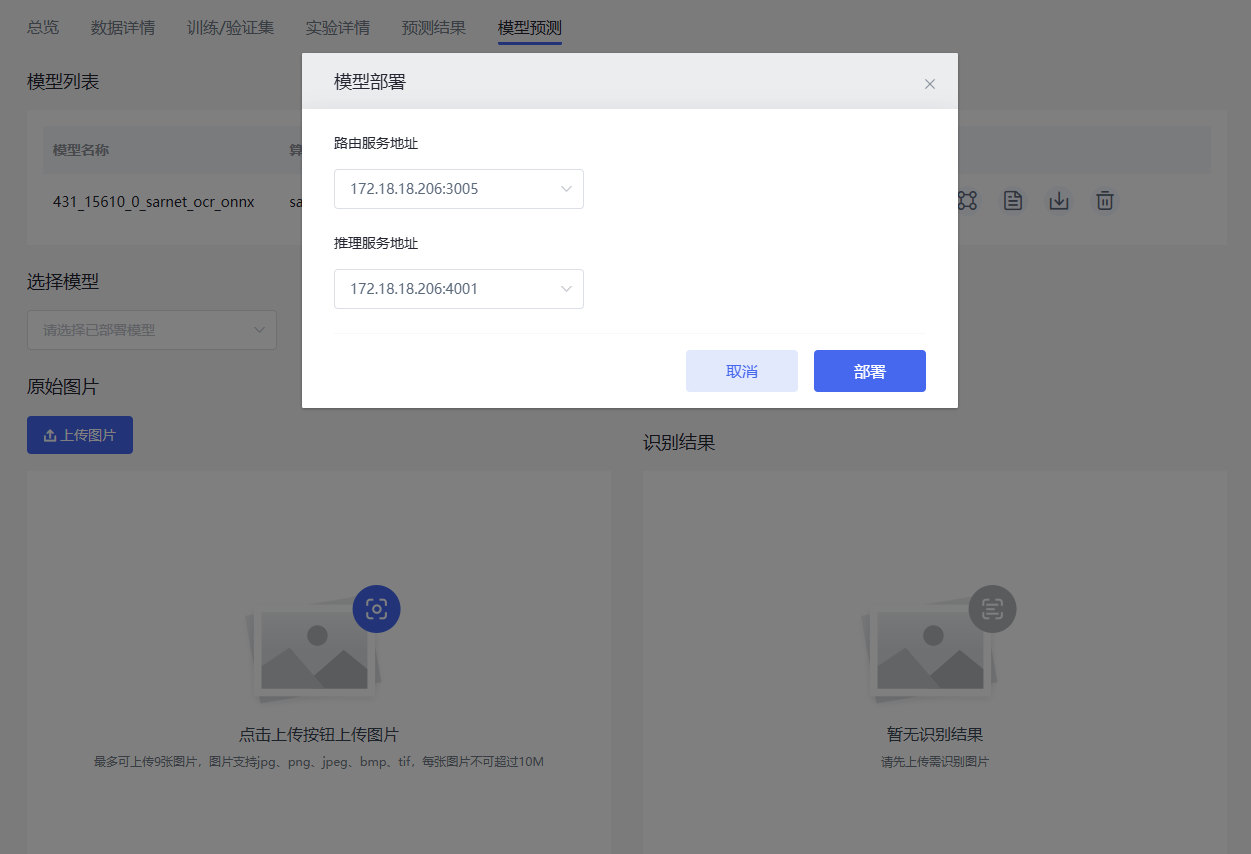
模型部署详细信息可参考模型部署。
模型预测#
模型部署完成后,点击上传图片按钮按要求上传图片,系统即可对此图片进行模型预测,预测结果会直接显示在右侧的识别结果栏内。
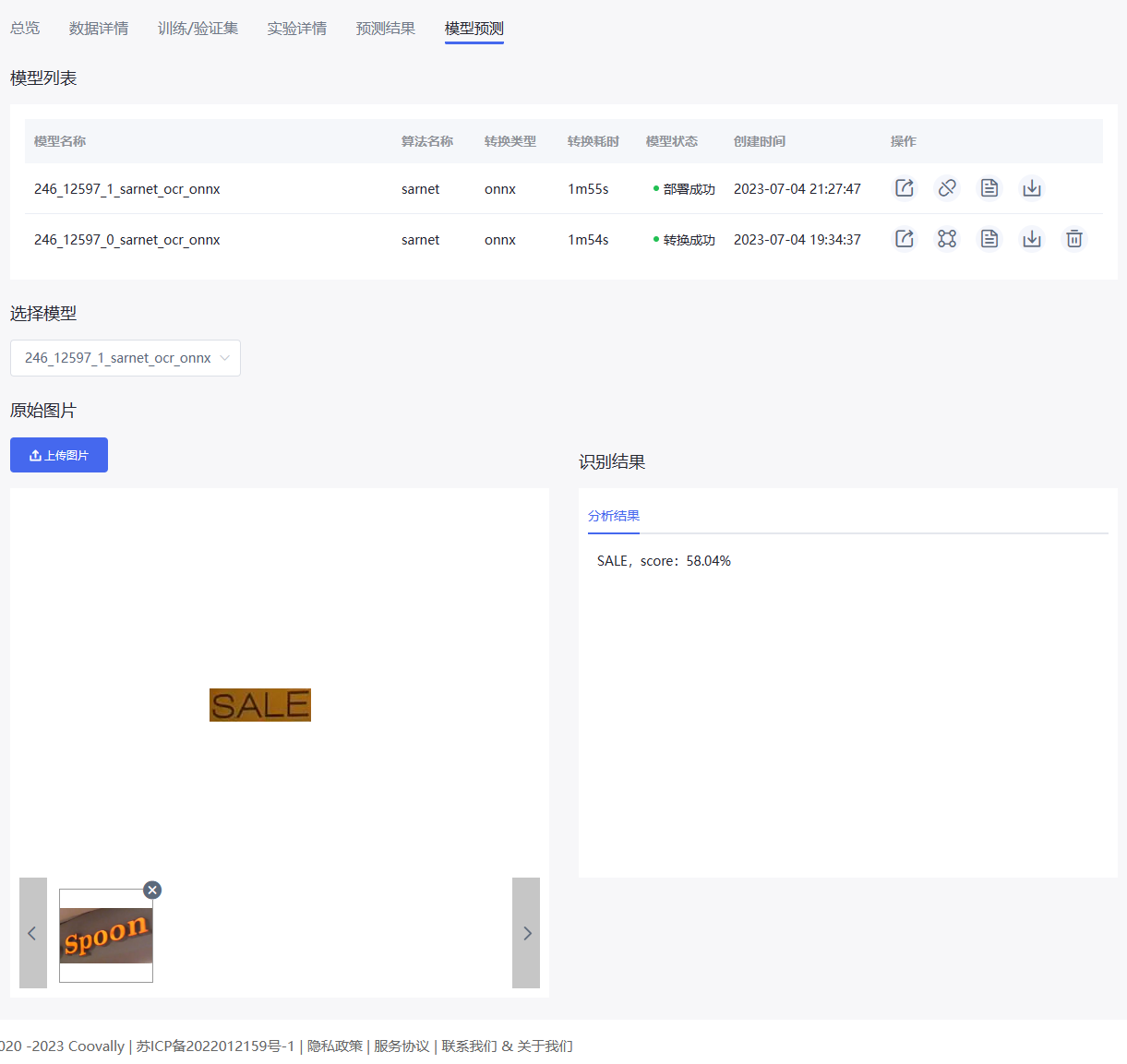
模型预测详细信息可参考模型预测。